AFL 全称是 American Fuzzy Lop,是一款基于代码覆盖率引导的程序模糊测试工具,通过将用户给定以及变异(mutation)得到的测试用例输入程序,获得程序代码的覆盖率,并将覆盖情况反馈给用例选取和变异过程,从而不断提升代码覆盖率,最终提高发现代码中出现漏洞的可能性。
先总结一下 AFL 的几个特点:
- 通过代码插桩(instrument)来记录每个测试用例输入程序后的代码覆盖率。
- 通过各种手段,对海量的测试用例进行精简。
- 类似于遗传算法,在 Fuzz 过程中对已有的测试用例进行变异,以生成新的用例。
进程交互#
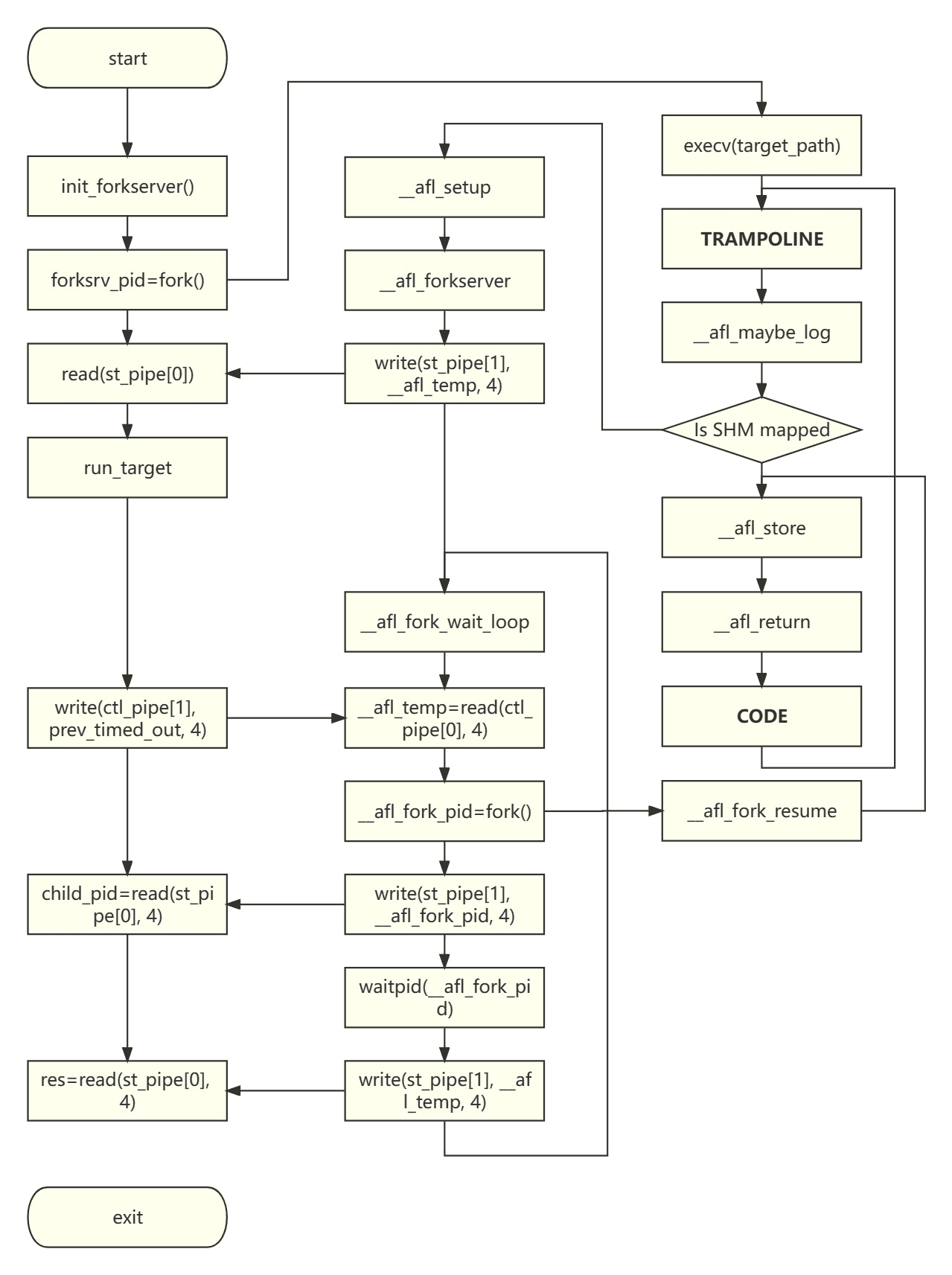
在最简单的情况下,整个 AFL 的 Fuzz 流程(campaign)由 3 个进程合作完成:
- Fuzzer:代码实现位于 afl-fuzz.c 文件中,是 Fuzz 主程序,负责维护测试用例的队列,在测试过程中调度用例输入程序。Fork Server 是 Fuzzer 的子进程,由其 fork 而来,这也是 Fuzz 过程中唯二的 fork 系统调用(除了 dumb mode 之外)。
- Fork Server:自身没有源文件,其代码由 afl-as 插桩时插入到了 Target 的汇编代码中。可以看做是被测程序 Target 的一个 wrapper,由 Fuzzer fork 出来以后常驻,与 Fuzzer 之间建立了两个 pipe 用于双向通信,此外 Fork Server 会与 Fuzzer 使用一块共享内存(shared memory)来传递代码覆盖率信息。
- Target:Target 的进程实例由 Fork Server fork 得到。每个分支、循环结构都被插桩,插入的代码会将代码执行覆盖情况写入共享内存,供 Fuzzer 读取。
这 3 个角色的流程图如下所示。
插桩#
程序插桩是一种基础的动态分析方法,通过在代码中插入探针(hook)代码来获得程序运行时的上下文信息。可以对源码进行插桩,也可以对中间代码或者二进制代码进行插桩。AFL 提供两种插桩模式:
- 直接读取由被测程序源码编译成的汇编代码(.s)文件,在关键指令 / 伪指令后插入需要插桩的代码。
- 将插桩过程实现为 LLVM 的 Pass(由于我在本地编译 llvm-mode 屡次失败,所以略过~)。
AFL 通过插桩来获得代码执行路径覆盖率。路径覆盖要求覆盖代码执行的每一条路径,不同的分支的组合成的路径算作是不同的,对于循环体内的语句,循环不同的次数同样也视为不同的路径。路径覆盖比分支覆盖和条件覆盖的粒度更细,可能会由于程序中包含的大量分支、循环结构而产生路径爆炸的问题,对于实际程序代码而言可以说是过于严苛了。
AFL 插桩的主要代码位于 afl-as.c 的 add_instrumentation() 函数中,被插入的探针代码位于 afl-as.h 中:
- 逐行读取汇编代码,通过字符串比对判断是否读到了代码段(.text)。
- 如果进入了代码段,那么就进入潜在的插桩区域,afl-as 重点关注这些行:
- 存在冒号(:)的函数名。
- .L等 gcc 和 clang 下的分支标记。
- jnz 等条件跳转语句(不包括无条件跳转 jmp)。
- 当读取到了上述这些关键语句后,立刻在其后插入如下的代码,每个关键位置都包含这样一份探针代码:
static const u8* trampoline_fmt_64 =
"\n"
"/* --- AFL TRAMPOLINE (64-BIT) --- */\n"
"\n"
".align 4\n"
"\n"
"leaq -(128+24)(%%rsp), %%rsp\n"
"movq %%rdx, 0(%%rsp)\n"
"movq %%rcx, 8(%%rsp)\n"
"movq %%rax, 16(%%rsp)\n"
"movq $0x%08x, %%rcx\n"
"call __afl_maybe_log\n"
"movq 16(%%rsp), %%rax\n"
"movq 8(%%rsp), %%rcx\n"
"movq 0(%%rsp), %%rdx\n"
"leaq (128+24)(%%rsp), %%rsp\n"
"\n"
"/* --- END --- */\n"
"\n";
其中 %08x 被 fprintf 替换为一个随机数,代表了这个代码位置的 ID。后续就用这些 ID 的组合来表达代码执行路径。
- 当读取完了所有行之后,在汇编文件最后插入另一个汇编代码段 main_payload_64,这段代码由探针代码中的 call __afl_maybe_log 调用,包含两部分功能:
- 第一次 call __afl_maybe_log,会执行初始化:
- Fork Server 通过 pipe 发消息给 Fuzzer 来告知开始了一次新的 fuzz。
- 连接(attach)共享内存。
- Fork Server fork 新的 Target 进程。
- 每一次,统计当前代码位置 ID 的路径覆盖信息。
- 第一次 call __afl_maybe_log,会执行初始化:
路径覆盖统计#
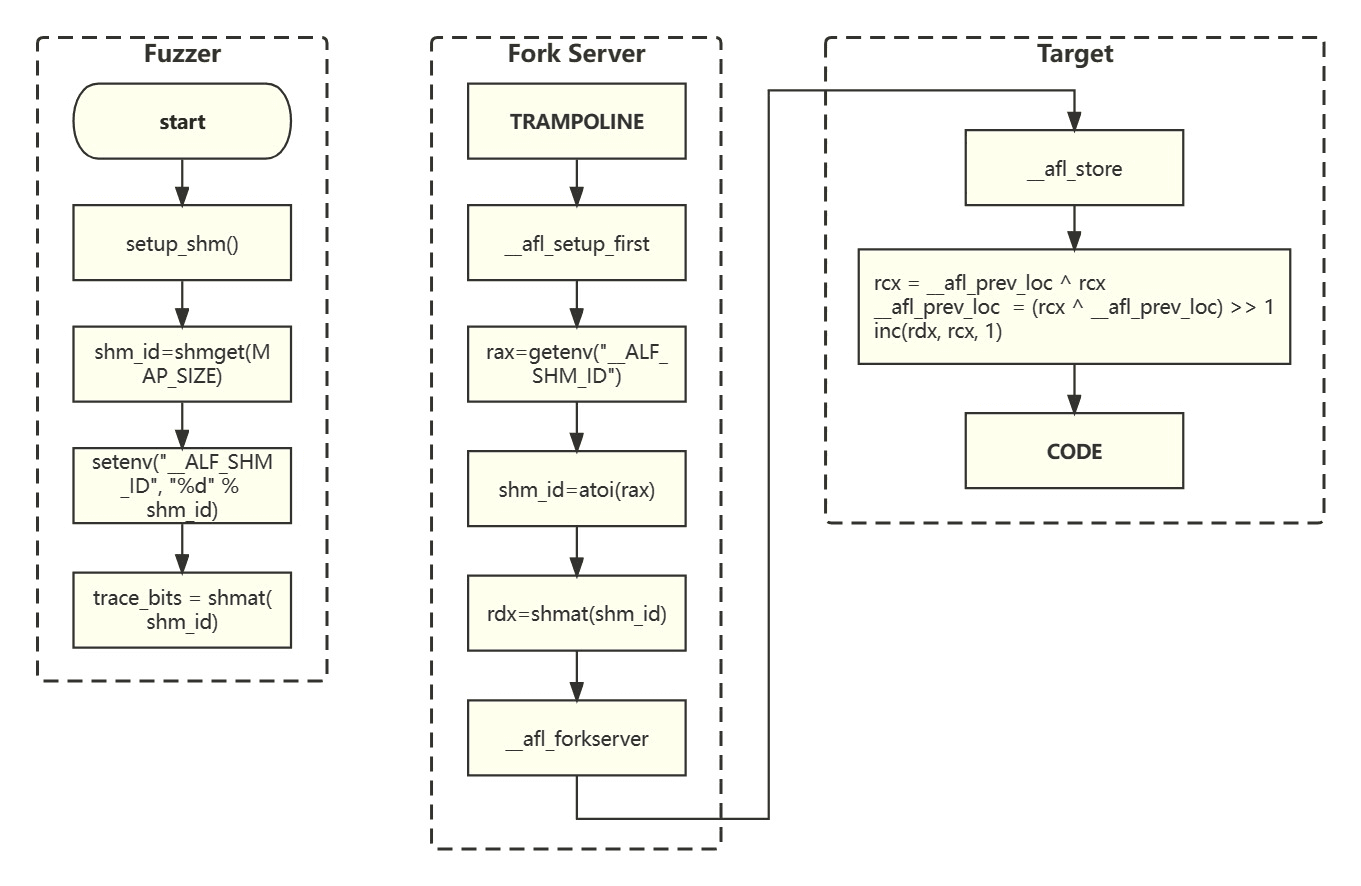
探针代码会将执行路径记录在共享内存的 Map 中,这块共享内存由 Fuzzer 分配,共享内存 ID 通过环境变量 __AFL_SHM_ID 传递给 Fork Server,在初始化步骤读取并且加载(attach),共享内存地址则直接供 Target 使用(因为 Target 是 Fork Server fork 出来的,二者全局变量取值是相同的)。
AFL 会在内存中开辟一块区域用作记录路径访问次数的 Map,Map 的 Key 为路径的 ID,Value 为该次 Fuzz 过程中访问到该路径的次数。AFL 把 ID 对最大路径数(MAP_SIZE)取模来将 ID 的取值限制在一个范围内,最基本的数组(连续内存)就能实现 Map 的功能。
AFL 通过代码位置 ID 来计算路径 ID 的方式也是有些意思的:
path_id = previous_location_id **xor** current_location_id
previous_location_id = (path_id **xor** previous_location_id) **>>** 1
map[path_id] ++
之所以要右移 1 位,是需要解决 A→B 和 B→A 算作不同,以及 A→A 和 B→B 也要算作不同的情况。
Fuzz#
AFL 的核心流程位于一个 1600 多行的函数 fuzz_one 中,对于每个队列中的 entry,都会传入该函数进行 fuzz,步骤可以概括为:
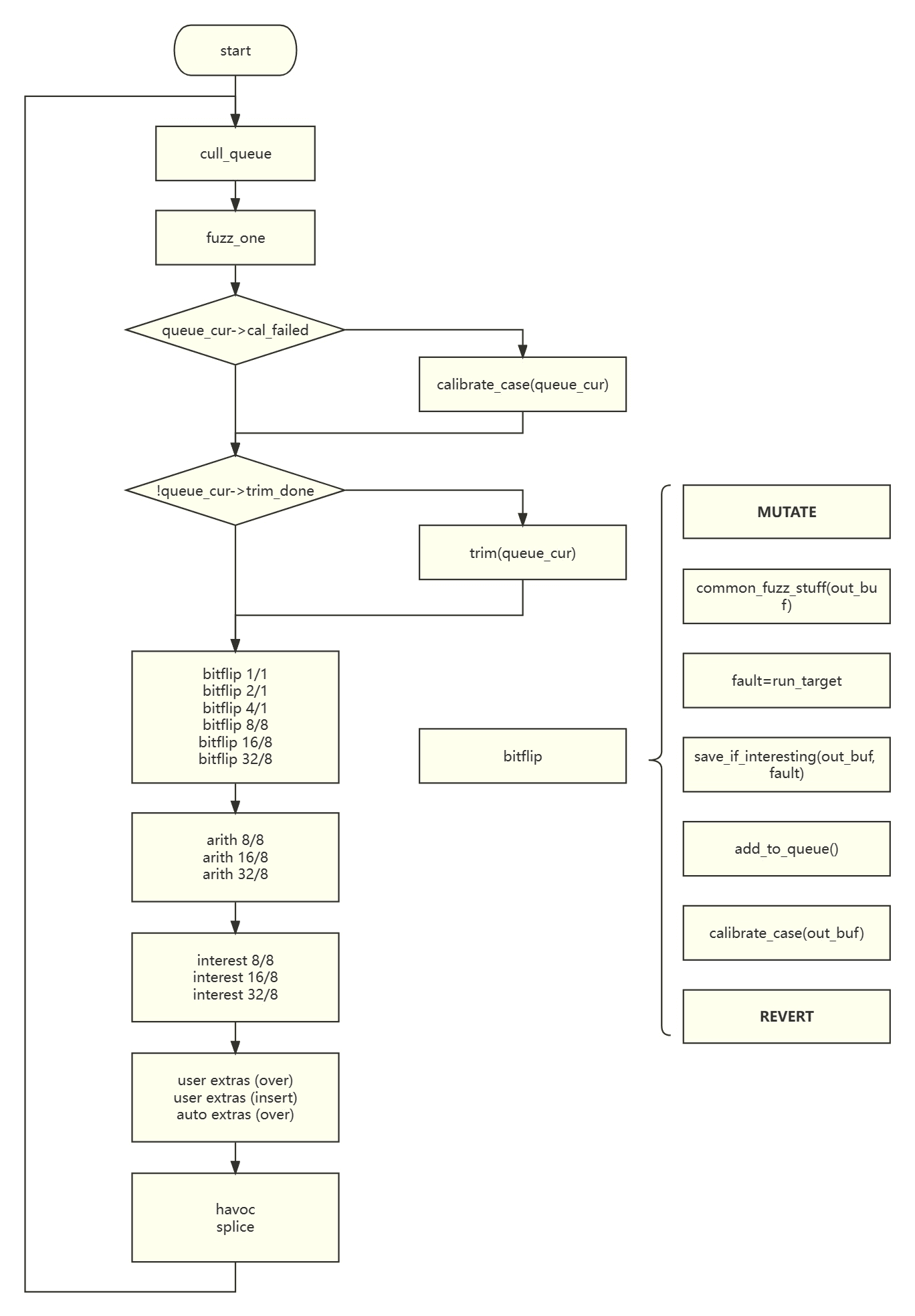
精简用例#
由于输入空间极为庞大,因此需要对测试用例进行精简,丢弃掉一部分看似无用的用例。
update_bitmap_score#
for (i = 0; i < MAP_SIZE; i++) {
if (trace_bits[i]) {
if (top_rated[i]) {
if (q->exec_us * q->len > top_rated[i]->exec_us * top_rated[i]->len) continue;
}
top_rated[i] = q;
}
q->trace_mini = ck_alloc(MAP_SIZE >> 3);
minimize_bits(q->trace_mini, trace_bits);
}
- 维护一个数组 top_rated,记录每个路径所被覆盖的用例 queue entry,如果该路径之前已备其他用例覆盖过,就比较二者的运行时间与 payload 长度的乘积,乘积更小的留在 top_rated 中。AFL 更偏向于执行之间更短、payload 长度更短的用例。
- 压缩 queue entry 的覆盖路径记录表 trace_bits 为一个 bitmap,trace_bits 中记录了访问每个路径的次数,而 trace_mini 中记录的则是每个路径是否有被访问过。
cull_queue#
for (i = 0; i < MAP_SIZE; i++) {
if (top_rated[i] && (temp_v[i >> 3] & (1 << (i & 7)))) {
/* Remove all bits belonging to the current entry from temp_v. */
}
top_rated[i]->favored = 1;
}
- 遍历 top_rated 中的每个 entry,当次 entry 所能覆盖的所有路径中存在还没有被其他 entry 覆盖到的,就将该 entry 覆盖的所有路径都记录到 temp_v 中,同时 entry 标记为 favored。
- 在 fuzz_one 中会以一定概率优先考虑 favored entry。
trim_case#
remove_len = next_p2(q->len) / 16;
while (remove_len >= next_p2(q->len) / 1024) {
u32 remove_pos = remove_len;
while(remove_pos < q->len) {
write_with_gap(in_buf, q->len, remove_pos, remove_len);
fault = run_target();
cksum = hash32(trace_bits);
if (cksum == q->exec_cksum) {
/* If the deletion had no impact on the trace, make it permanent. */
......
} else remove_pos += remove_len;
}
remove_len >>= 1;
}
- 对每个测试用例单独进行修剪,尽量缩短其长度,以加快 fuzz 速度。
- 逐个删除 payload 中的每个固定长度的段,然后尝试运行,判断是否产生不同的覆盖。如果删除了之后没有影响,那就将删除后的 payload 保存到 queue entry 对应的文件中。
calibrate_case#
for (stage_cur = 0; stage_cur < 16; stage_cur++) {
write_to_testcase(use_mem, q->len);
fault = run_target();
cksum = hash32(trace_bits, MAP_SIZE, HASH_CONST);
if (q->exec_cksum != cksum) {
hnb = has_new_bits(virgin_bits);
for (i = 0; i < MAP_SIZE; i++) {
if (!var_bytes[i] && first_trace[i] != trace_bits[i]) {
var_bytes[i] = 1;
stage_max = 40;
}
}
} else {
q->exec_cksum = cksum;
memcpy(first_trace, trace_bits, MAP_SIZE);
}
update_bitmap_score(q);
/* Mark q->has_new_cov or mark_as_variable(q)
}
- calibrate 函数校验测试用例是否会在多次执行中产生不同的覆盖情况,每个测试用例默认重复 8 次,如果某次路径覆盖结果变化了,那就增加重复执行次数到 40 次。
- 如果产生了新的覆盖,就记录到 q->has_new_cov,不过我并没有找到实际使用这个变量的代码。
变异#
- bitflip:对逐个 1/2/4 bit 做翻转,对逐个 1/2/4 byte 做翻转。
- arith:对逐个 1/2/4 byte 加上 / 减去 1-35 的整数。
- interest:对逐个 1/2/4 byte 替换为定义好的特殊值。
- extras:在尾部添加 / 在中间插入定义好的 token。
- havoc(大破坏):叠加随机次数的随机变异操作。
- splice:随机选择队列中的另一个输入,选择一段适合长度的子串拼接到当前 payload 中。
总结#
在 Fuzz 的众多工具中,AFL 由于出现的较早,所以其所做的工作还是较为简单的,但是超过八千行的 C 代码,以及面向过程的编程范式(甚至有超过 1600 行代码的单个函数,各种 goto),仍让一个刚入门的 Fuzzer(我)头疼不已。
参考资料#
afl 源码阅读_最爱・american fuzzy lop_学习才是永恒的博客 - CSDN 博客
AFL 二三事 —— 源码分析 - FreeBuf 网络安全行业门户
[原创] AFL afl_fuzz.c 详细分析 - 二进制漏洞 - 看雪 - 安全社区 | 安全招聘 | kanxue.com