AFL, short for American Fuzzy Lop, is a code coverage-guided program fuzzing tool. It takes user-provided and mutated test cases as input to the program to obtain code coverage information and provides feedback on coverage to the test case selection and mutation process, continuously improving code coverage and increasing the likelihood of discovering vulnerabilities in the code.
Let's summarize a few characteristics of AFL:
- It uses code instrumentation to record code coverage after each test case is inputted into the program.
- It employs various methods to reduce a large number of test cases.
- Similar to a genetic algorithm, it mutates existing test cases during the fuzzing process to generate new ones.
Interactive Process#
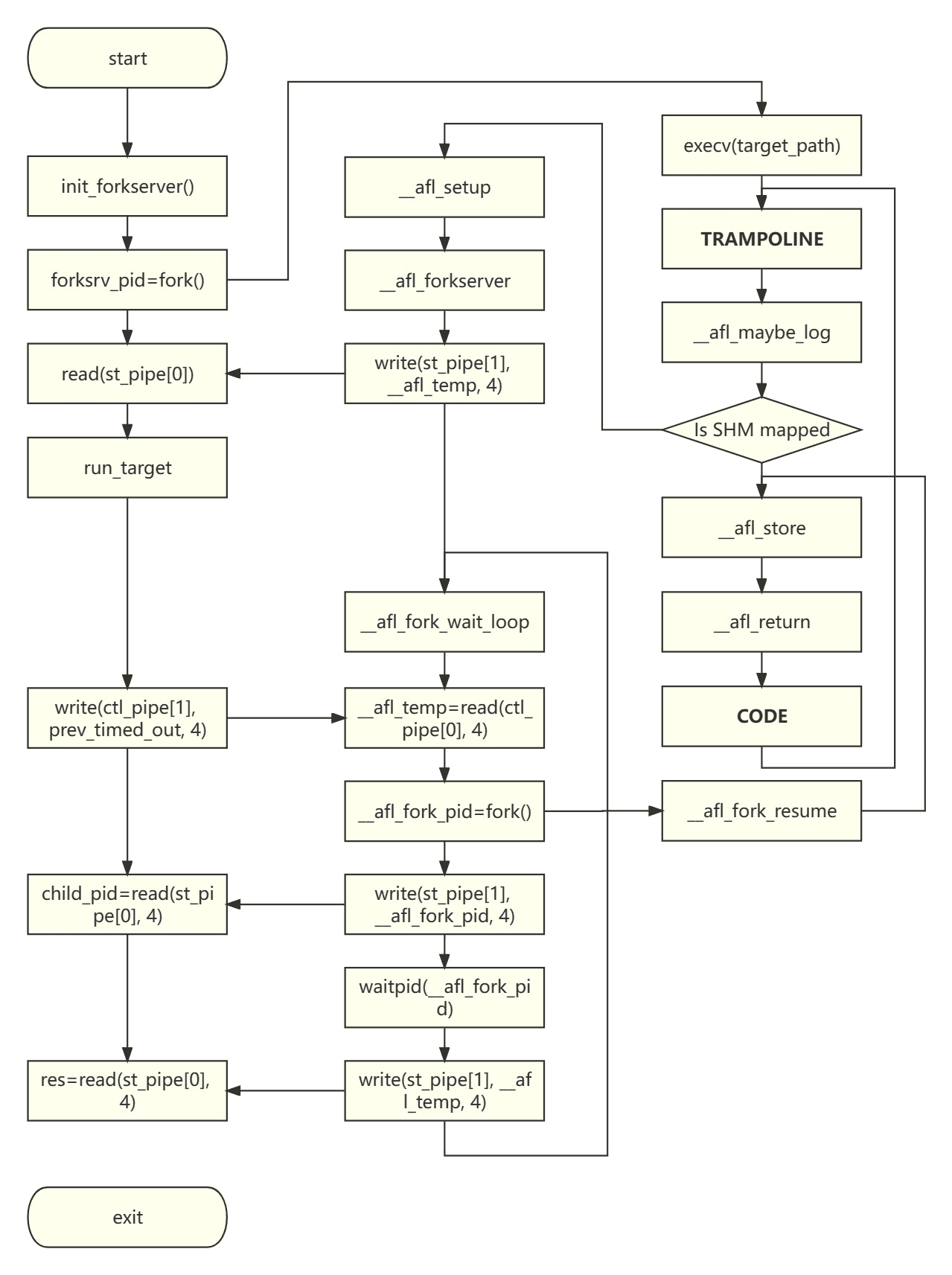
In the simplest case, the AFL fuzzing process (campaign) is completed by three cooperating processes:
- Fuzzer: The code implementation is located in the afl-fuzz.c file and serves as the main fuzzing program. It is responsible for maintaining the test case queue and scheduling test cases to input into the program during the testing process. The Fork Server is a child process of the Fuzzer, created by forking, and is the only fork system call (except for dumb mode) in the fuzzing process.
- Fork Server: It does not have its own source file. Its code is inserted into the assembly code of the target program during AFL instrumentation. It can be seen as a wrapper for the target program, created by forking from the Fuzzer. It resides permanently and establishes two pipes for bidirectional communication with the Fuzzer. Additionally, the Fork Server uses shared memory to pass code coverage information to the Fuzzer.
- Target: The process instance of the Target is forked from the Fork Server. Each branch and loop structure is instrumented, and the inserted code writes the code execution coverage to shared memory for the Fuzzer to read.
The flowchart of these three roles is shown below.
Instrumentation#
Program instrumentation is a fundamental dynamic analysis method that involves inserting probe code into the code to obtain runtime context information. It can be applied to source code, intermediate code, or binary code. AFL provides two instrumentation modes:
- Directly read the assembly code (.s) file compiled from the target program's source code and insert the required instrumentation code after key instructions/pseudo-instructions.
- Implement the instrumentation process as an LLVM Pass (skipped due to repeated failures in compiling llvm-mode locally).
AFL obtains code coverage by instrumentation to achieve path coverage. Path coverage requires covering every path of code execution, considering different combinations of branches as different paths. For statements inside a loop, different numbers of loop iterations are also considered as different paths. Path coverage has a finer granularity than branch coverage and condition coverage. However, it may lead to the problem of path explosion due to a large number of branches and loop structures in the program, which can be too strict for practical program code.
The main code for AFL instrumentation is located in the add_instrumentation() function in afl-as.c, and the inserted probe code is in afl-as.h:
- Read the assembly code line by line and determine if the code segment (.text) is reached by string comparison.
- If the code segment is entered, potential instrumentation areas are entered. AFL focuses on the following lines:
- Function names with colons (:).
- Branch markers like .L under gcc and clang.
- Conditional jump statements like jnz (excluding unconditional jump jmp).
- After reading these key statements, immediately insert the following code snippet, which is the probe code, after each key position:
static const u8* trampoline_fmt_64 =
"\n"
"/* --- AFL TRAMPOLINE (64-BIT) --- */\n"
"\n"
".align 4\n"
"\n"
"leaq -(128+24)(%%rsp), %%rsp\n"
"movq %%rdx, 0(%%rsp)\n"
"movq %%rcx, 8(%%rsp)\n"
"movq %%rax, 16(%%rsp)\n"
"movq $0x%08x, %%rcx\n"
"call __afl_maybe_log\n"
"movq 16(%%rsp), %%rax\n"
"movq 8(%%rsp), %%rcx\n"
"movq 0(%%rsp), %%rdx\n"
"leaq (128+24)(%%rsp), %%rsp\n"
"\n"
"/* --- END --- */\n"
"\n";
The %08x is replaced by fprintf with a random number, representing the ID of the code location. These ID combinations are used to represent code execution paths.
After reading all the lines, another assembly code segment, main_payload_64, is inserted at the end of the assembly file. This code segment is called by the call __afl_maybe_log in the probe code and includes two parts:
- The first call to __afl_maybe_log initializes:
- The Fork Server sends a message to the Fuzzer via a pipe to indicate the start of a new fuzzing.
- Connection (attach) to shared memory.
- The Fork Server forks a new Target process.
- For each subsequent call, it records the path coverage information for the current code location ID.
Path Coverage Statistics#
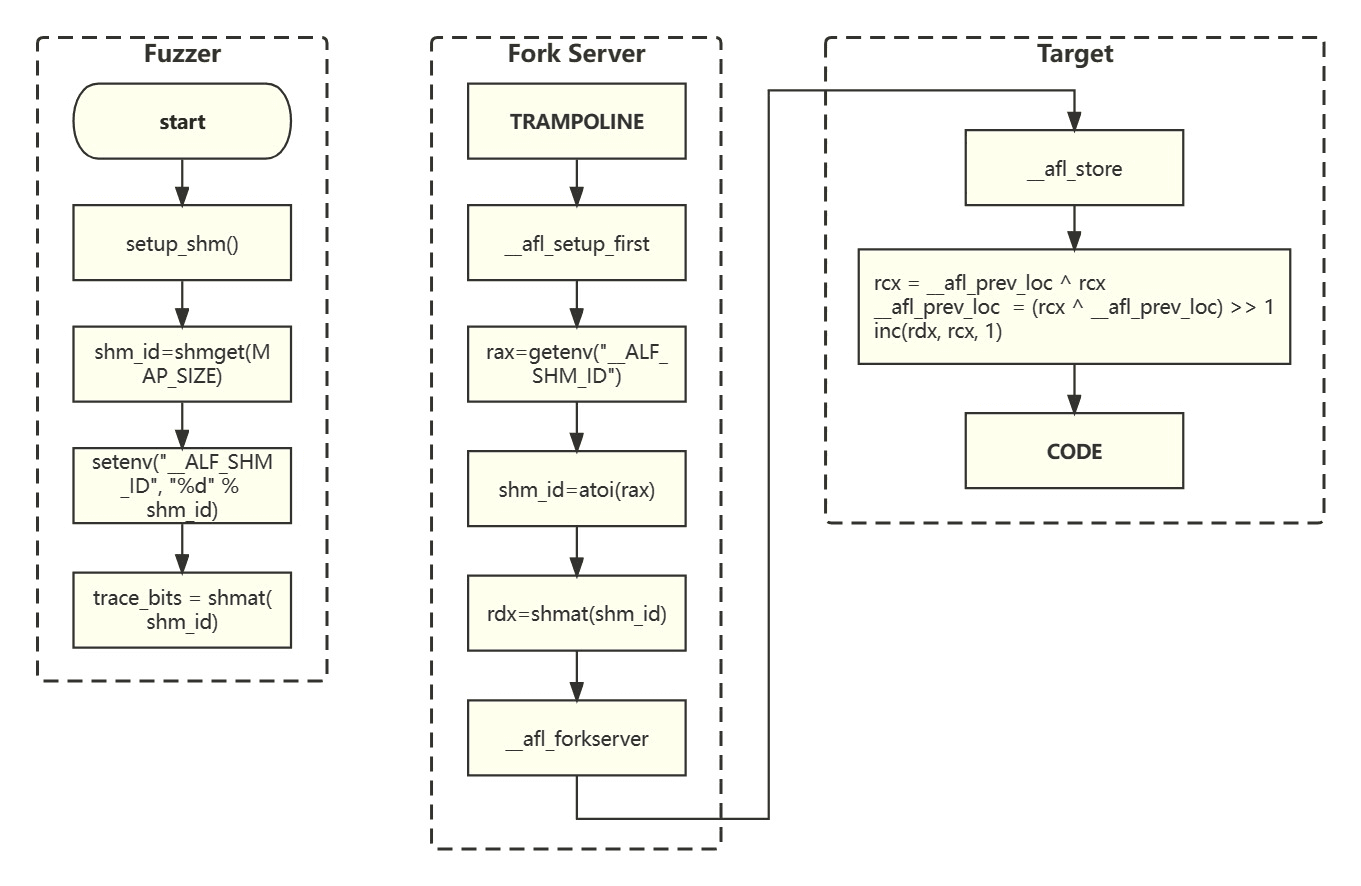
The probe code records the execution paths in the shared memory map. The Fuzzer allocates this shared memory, and the shared memory ID is passed to the Fork Server via the __AFL_SHM_ID environment variable, which is read and loaded (attach) during the initialization step. The shared memory address is directly used by the Target (since the Target is forked from the Fork Server, their global variable values are the same).
AFL allocates a region in memory to serve as a map for recording the number of times each path is visited. The key of the map is the ID of the path, and the value is the number of times the path was visited during a fuzzing process. AFL limits the ID values to a range by taking the modulo of the ID pairs with the maximum number of paths (MAP_SIZE). The basic array (contiguous memory) can implement the map's functionality.
AFL calculates the path ID based on the code location ID in an interesting way:
path_id = previous_location_id **xor** current_location_id
previous_location_id = (path_id **xor** previous_location_id) **>>** 1
map[path_id] ++
The right shift by 1 bit is necessary to handle cases where A→B and B→A are considered different paths, as well as A→A and B→B being considered different paths.
Fuzz#
The core process of AFL is in a function called fuzz_one, which is over 1600 lines long. For each entry in the queue, it is passed to this function for fuzzing. The steps can be summarized as follows:
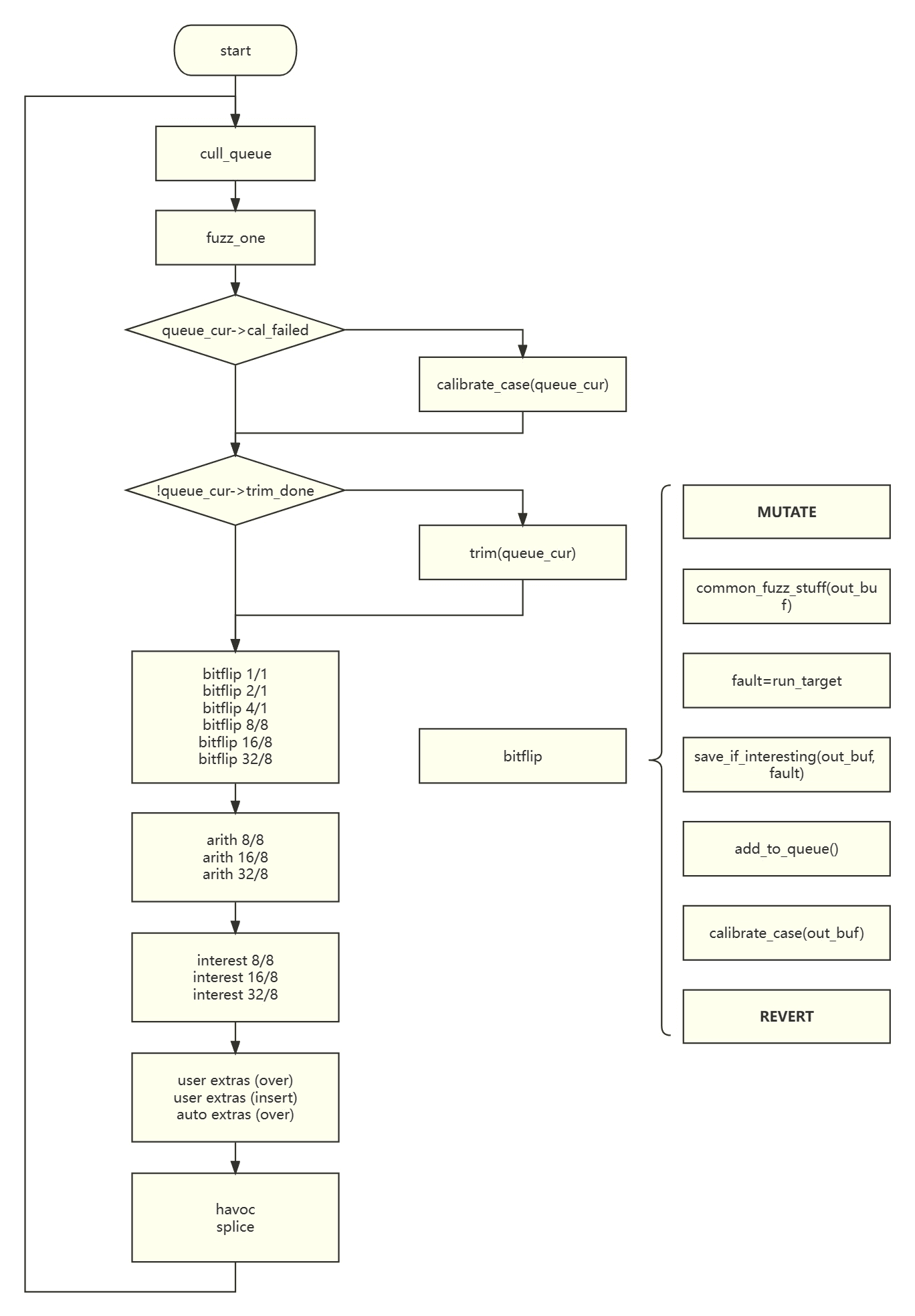
Trimming Test Cases#
Due to the enormous input space, test cases need to be trimmed to discard seemingly useless ones.
update_bitmap_score#
for (i = 0; i < MAP_SIZE; i++) {
if (trace_bits[i]) {
if (top_rated[i]) {
if (q->exec_us * q->len > top_rated[i]->exec_us * top_rated[i]->len) continue;
}
top_rated[i] = q;
}
q->trace_mini = ck_alloc(MAP_SIZE >> 3);
minimize_bits(q->trace_mini, trace_bits);
}
- Maintains an array called top_rated, which records the queue entry covering each path. If the path has been covered by another entry before, it compares the product of the execution time and payload length between the two entries. The entry with a smaller product remains in top_rated. AFL tends to favor shorter execution time and payload length.
- Compresses the queue entry's coverage path record table, trace_bits, into a bitmap. trace_bits records the number of times each path is visited, while trace_mini records whether each path has been visited.
cull_queue#
for (i = 0; i < MAP_SIZE; i++) {
if (top_rated[i] && (temp_v[i >> 3] & (1 << (i & 7)))) {
/* Remove all bits belonging to the current entry from temp_v. */
}
top_rated[i]->favored = 1;
}
- Iterates through each entry in top_rated. If there are paths covered by the current entry that have not been covered by other entries, it records all the paths covered by that entry in temp_v and marks the entry as favored.
- In fuzz_one, favored entries are given priority with a certain probability.
trim_case#
remove_len = next_p2(q->len) / 16;
while (remove_len >= next_p2(q->len) / 1024) {
u32 remove_pos = remove_len;
while(remove_pos < q->len) {
write_with_gap(in_buf, q->len, remove_pos, remove_len);
fault = run_target();
cksum = hash32(trace_bits);
if (cksum == q->exec_cksum) {
/* If the deletion had no impact on the trace, make it permanent. */
......
} else remove_pos += remove_len;
}
remove_len >>= 1;
}
- Trims each test case individually to minimize its length and speed up the fuzzing process.
- Iteratively deletes fixed-length segments from the payload one by one and tries to run it. It checks if the deletion has any impact on the coverage. If there is no impact, it saves the modified payload to the file corresponding to the queue entry.
calibrate_case#
for (stage_cur = 0; stage_cur < 16; stage_cur++) {
write_to_testcase(use_mem, q->len);
fault = run_target();
cksum = hash32(trace_bits, MAP_SIZE, HASH_CONST);
if (q->exec_cksum != cksum) {
hnb = has_new_bits(virgin_bits);
for (i = 0; i < MAP_SIZE; i++) {
if (!var_bytes[i] && first_trace[i] != trace_bits[i]) {
var_bytes[i] = 1;
stage_max = 40;
}
}
} else {
q->exec_cksum = cksum;
memcpy(first_trace, trace_bits, MAP_SIZE);
}
update_bitmap_score(q);
/* Mark q->has_new_cov or mark_as_variable(q)
}
- The calibrate function verifies if a test case produces different coverage results in multiple executions. Each test case is repeated 8 times by default, and if the coverage result changes in any of the executions, the number of repetitions is increased to 40.
- If new coverage is generated, it is recorded in q->has_new_cov. However, I did not find the actual code that uses this variable.
Mutation#
- bitflip: Flips 1/2/4 bits one by one and flips 1/2/4 bytes one by one.
- arith: Adds/subtracts integers from 1 to 35 to 1/2/4 bytes one by one.
- interest: Replaces 1/2/4 bytes one by one with predefined special values.
- extras: Appends/inserts predefined tokens at the end or in the middle of the payload.
- havoc: Applies a random number of random mutation operations.
- splice: Randomly selects another input from the queue, selects a substring of suitable length, and concatenates it with the current payload.
Summary#
Among the various fuzzing tools, AFL's work is relatively simple due to its early appearance. However, with over 8,000 lines of C code and a procedural programming paradigm (including a single function with over 1,600 lines of code and various goto statements), it still gives a beginner fuzz tester (like me) a headache.
References: