The mykter/afl-training repository contains a series of materials that can help beginners quickly master how to use afl++ for fuzz testing open source software.
Setup#
Considering that pulling the built ghcr.io/mykter/fuzz-training directly may take longer, I chose to build the image from scratch locally using a Dockerfile and then run the container.
- build: You can add
ARG http_proxyin the Dockerfile, and then add--build-arg "http_proxy=http://127.0.0.1:7890"in the docker build command, while configuring the parameter--network=host(which is different from docker run--net=host!), so that the build process can connect to the network proxy. Add the git proxy (git config --global http-proxy $http_proxy) in an appropriate position in the Dockerfile to speed up git pull. - run: Since the proxy programs for accessing the external network and scientific internet access are running on the host, and my container cannot connect to the host's IP (which should be 172.27.0.1) and proxy port during runtime, I can only choose to run the container in host mode (
--net=host), avoiding the hassle of port mapping, host IP, etc.
libxml2#
libxml2 is a popular XML processing library implemented in C, and its following features make it very suitable for practicing fuzzing:
- Stateless
- No network communication and file read/write
- Detailed documentation, explicit API, no need for additional analysis of internal fuzz interfaces
- Focused functionality, simple (processing XML), runs relatively fast
The CVE (Common Vulnerabilities & Exposures) considered here is CVE-2015-8317: The xmlParseXMLDecl function in parser.c triggers an out-of-bounds heap read when handling incomplete encoding and incomplete XML declarations.
/**
* xmlParseXMLDecl:
* @ctxt: an XML parser context
*
* parse an XML declaration header
*
* [23] XMLDecl ::= '<?xml' VersionInfo EncodingDecl? SDDecl? S? '?>'
*/
void xmlParseXMLDecl(xmlParserCtxtPtr ctxt) { ... }
In parser.c, the xmlParseXMLDecl function is responsible for parsing the XML declaration part, which refers to the content typically placed in the first line of an XML document:
<?xml version="1.0" encoding="UTF-8"?>
Idea#
Although the problem lies within the internal functionality of this function, it is not necessary to test only this function:
- I feel that the vulnerability in XML declaration parsing caused by incomplete string values should be easy to discover during fuzzing, and the efficiency difference between generating XML documents that only contain declarations and complete XML documents for fuzzing should not be too large.
- The parameter of the
xmlParseXMLDeclfunction is the context of the XML parsing process (xmlParserCtxtPtr), and directly generating and mutating this context is a very cumbersome and inefficient task; this context should be generated by a higher-level API.
Based on these two considerations, I found an example program related to xmlParserCtxtPtr, which serves as the fuzzing harness:
#include <stdio.h>
#include <libxml/parser.h>
#include <libxml/tree.h>
/**
* exampleFunc:
* @filename: a filename or an URL
*
* Parse and validate the resource and free the resulting tree
*/
static void exampleFunc(const char *filename) {
xmlParserCtxtPtr ctxt; /* the parser context */
xmlDocPtr doc; /* the resulting document tree */
/* create a parser context */
ctxt = xmlNewParserCtxt();
if (ctxt == NULL) {
fprintf(stderr, "Failed to allocate parser context\n");
return;
}
/* parse the file, activating the DTD validation option */
doc = xmlCtxtReadFile(ctxt, filename, NULL, XML_PARSE_DTDVALID);
/* check if parsing succeeded */
if (doc == NULL) {
fprintf(stderr, "Failed to parse %s\n", filename);
} else {
/* check if validation succeeded */
if (ctxt->valid == 0)
fprintf(stderr, "Failed to validate %s\n", filename);
/* free up the resulting document */
xmlFreeDoc(doc);
}
/* free up the parser context */
xmlFreeParserCtxt(ctxt);
}
int main(int argc, char **argv) {
if (argc != 2)
return(1);
/*
* this initializes the library and checks potential ABI mismatches
* between the version it was compiled for and the actual shared
* library used.
*/
LIBXML_TEST_VERSION
exampleFunc(argv[1]);
/*
* Cleanup function for the XML library.
*/
xmlCleanupParser();
/*
* this is to debug memory for regression tests
*/
xmlMemoryDump();
return(0);
}
The program logic is very simple: it first reads a filename from the command line arguments, constructs a brand new xmlParserCtxtPtr instance, and then reads and parses the text from the filename, with the parsing process tracked by the xmlParserCtxtPtr instance.
Next, compile the libxml2 library and the harness executable:
cd libxml2
CC=afl-clang-fast ./autogen.sh
AFL_USE_ASAN=1 make -j 4
cd ..
AFL_USE_ASAN=1 afl-clang-fast ./harness.c -I libxml2/include libxml2/.libs/libxml2.a -lz -lm -o fuzzer
Then start fuzzing:
AFL_SKIP_CPUFREQ=1 afl-fuzz -i inputs/ -o outputs/ ./fuzzer @@
Fuzz result#


Persistent Mode#
The harness provided in the reference answer uses AFL-LLVM's Persistent Mode.
In basic AFL, the fuzzer main program will fork a child process as a fork_server. The fuzzing process inevitably executes the target program multiple times; to avoid the system overhead of loading the target program multiple times with exec, AFL allows the fork_server to execute the fork command to produce a new target.
To further reduce the overhead caused by forking, persistent mode allows the harness code to explicitly loop and call the API being tested, in the main function of the harness like this:
while (__AFL_LOOP(1000)) {
/* Setup function call, e.g. struct target *tmp = libtarget_init() */
/* Call function to be fuzzed, e.g.: */
target_function(buf, len);
/* Reset state. e.g. libtarget_free(tmp) */
}
The compiled XML document is generated in memory, completely eliminating the need to write to a file, and is directly input to the fuzzer. In AFL, test cases are redirected to STDIN, which are then read by the target program. AFL++ provides a shared memory channel to facilitate the transfer of test cases between the fuzzer and the target. To utilize this feature, simply declare the macro __AFL_FUZZ_INIT();.
Additionally, although persistent mode can avoid executing the target's initialization code each time, this initialization code will still be executed when the fork_server forks the target process. To reuse the state after the program has run these initialization codes, AFL++'s method is to delay the initialization of the fork server (from the beginning of the original program) to a user-specified location.
/* This one can be called from user code when deferred forkserver mode
is enabled. */
void __afl_manual_init(void) {
static u8 init_done;
if (...) {...}
if (!init_done) {
__afl_start_forkserver();
init_done = 1;
}
}
Combining the above three features: persistent mode, shared memory fuzzing, and deferred initialization, ultimately forms the libxml2 harness. The macros __AFL_FUZZ_TESTCASE_BUF and __AFL_FUZZ_TESTCASE_LEN represent the shared memory address and the size of the test case, respectively.
#include "libxml/parser.h"
#include "libxml/tree.h"
#include <unistd.h>
__AFL_FUZZ_INIT();
int main(int argc, char **argv) {
#ifdef __AFL_HAVE_MANUAL_CONTROL
__AFL_INIT();
#endif
unsigned char *buf = __AFL_FUZZ_TESTCASE_BUF; // must be after __AFL_INIT
xmlInitParser();
while (__AFL_LOOP(1000)) {
int len = __AFL_FUZZ_TESTCASE_LEN;
xmlDocPtr doc = xmlReadMemory((char *)buf, len, "https://mykter.com", NULL, 0);
if (doc != NULL) {
xmlFreeDoc(doc);
}
}
xmlCleanupParser();
return(0);
}
With the help of AFL's built-in XML dictionary, input document mutations can be further enhanced when certain syntax is known:
AFL_SKIP_CPUFREQ=1 afl-fuzz -i inputs/ -o outputs/ -x ~/AFLplusplus/dictionaries/xml.dict ./fuzzer


The crash cases found are quite numerous, and indeed there are cases of unterminated encoding value as described in the CVE.
Heartbleed#
CVE-2014-0160 is a very famous "Heartbleed" vulnerability that existed in versions of OpenSSL prior to 1.0.1g.
To speed up the fuzzing process, I incorporated persistent mode, shared memory, and deferred initialization while modifying handshake.cc.
#include <openssl/ssl.h>
#include <openssl/err.h>
#include <assert.h>
#include <stdint.h>
#include <stddef.h>
#include <unistd.h>
#ifndef CERT_PATH
# define CERT_PATH
#endif
__AFL_FUZZ_INIT();
SSL_CTX *Init() {
SSL_library_init();
SSL_load_error_strings();
ERR_load_BIO_strings();
OpenSSL_add_all_algorithms();
SSL_CTX *sctx;
assert (sctx = SSL_CTX_new(TLSv1_method()));
/* These two files were created with this command:
openssl req -x509 -newkey rsa:512 -keyout server.key \
-out server.pem -days 9999 -nodes -subj /CN=a/
*/
assert(SSL_CTX_use_certificate_file(sctx, "server.pem",
SSL_FILETYPE_PEM));
assert(SSL_CTX_use_PrivateKey_file(sctx, "server.key",
SSL_FILETYPE_PEM));
return sctx;
}
int main() {
SSL_CTX *sctx = Init();
#ifdef __AFL_HAVE_MANUAL_CONTROL
__AFL_INIT();
#endif
unsigned char *buf = __AFL_FUZZ_TESTCASE_BUF;
while (__AFL_LOOP(1000))
{
SSL *server = SSL_new(sctx);
BIO *sinbio = BIO_new(BIO_s_mem());
BIO *soutbio = BIO_new(BIO_s_mem());
SSL_set_bio(server, sinbio, soutbio);
SSL_set_accept_state(server);
/* TODO: To spoof one end of the handshake, we need to write data to sinbio
* here */
int len = __AFL_FUZZ_TESTCASE_LEN;
BIO_write(sinbio, buf, len);
SSL_do_handshake(server);
SSL_free(server);
}
SSL_CTX_free(sctx);
return 0;
}
The fuzzing results are shown in the images, with suspected instability possibly related to reusing the SSL Context.


Vulnerability#
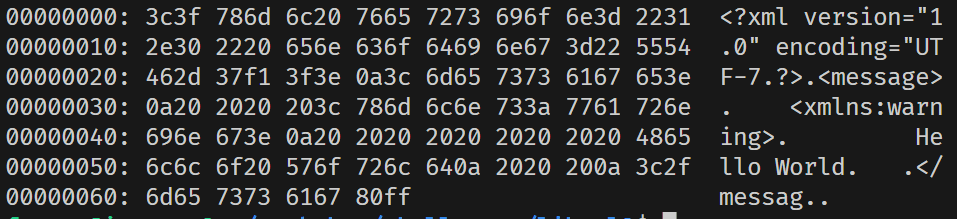
The xxd command can output file data in hexadecimal format (it is said that xxd's more powerful feature is to support dumping modified data to files).
![]()

- byte 0: SSL packet type, here 18 corresponds to TLS1_RT_HEARTBEAT.
- byte 1-2: SSL version, here 0301 represents TLS1.0, 0302 represents 1.1, 0303 represents 1.2, and here 03f5 is likely a version number automatically generated by the fuzzer, which may not correspond to any actual version, but the TLS server can still accept such a version number due to some fallback logic.
- byte 3-4: Length of the complete TLS packet (including header), here 0005 is also likely generated by the fuzzer, which is unreasonable, but the core issue of this vulnerability does not lie here.
- byte 5: TLS heartbeat type, 1 corresponds to request, 2 corresponds to response. Here it is sent from the client to the server, so it is 1.
- byte 6: Heartbeat payload length.
- Others: Heart payload data, the length of the data must conform to byte 6.
According to the normal processing logic, the server will echo (echo) the payload length and data of the request, simplified code logic as follows:
int
tls1_process_heartbeat(SSL *s) {
unsigned char *p = &s->s3->rrec.data[0], *pl;
/* Read type and payload length first */
hbtype = *p++;
n2s(p, payload);
pl = p;
if (hbtype == TLS1_HB_REQUEST) {
/* Allocate memory for the response, size is 1 byte
* message type, plus 2 bytes payload length, plus
* payload, plus padding
*/
buffer = OPENSSL_malloc(1 + 2 + payload + padding);
bp = buffer;
/* Enter response type, length and copy payload */
*bp++ = TLS1_HB_RESPONSE;
s2n(payload, bp);
memcpy(bp, pl, payload);
}
}
If an attacker provides a larger payload length without providing enough payload data, the server will allocate a response buffer based on the payload length and copy the payload length of data from the payload data buffer to the response buffer, resulting in the payload length immediately following the memory data being leaked to the response and sent to the attacker.
sendmail#1301#
The vulnerability to be tested is CVE-1999-0206. The code repository has already provided main.c as the harness code, and the target function being tested is mime7to8. This function is responsible for parsing text encoded in base64 or quoted-printable into actual data.
- base64: Uses 64 characters (6 bits) to represent binary data, meaning that 3 bytes of data need to be encoded into 4 characters.
- quoted-printable: For non-printable ASCII characters, its hexadecimal character representation is prefixed with an equal sign, using three characters for encoding.

AFL-training recommends using persistent mode and multicore parallelism during fuzzing. Since the ENVELOPE structure seems to lack a member that can directly store strings, and a temporary filename must be specified, shared memory cannot be used to directly pass test cases.
In addition to shared memory, deferred initialization also seems to have little effect, as the initialization code appears simple and does not take much time, so I only used __AFL_LOOP.
#include "my-sendmail.h"
#include <assert.h>
int main(int argc, char **argv)
{
HDR *header;
register ENVELOPE *e;
FILE *temp;
while (__AFL_LOOP(1000))
{
temp = fopen(argv[1], "r");
assert(temp != NULL);
header = (HDR *)malloc(sizeof(struct header));
header->h_field = "Content-Transfer-Encoding";
header->h_value = "quoted-printable";
header->h_link = NULL;
header->h_flags = 0;
e = (ENVELOPE *)malloc(sizeof(struct envelope));
e->e_id = "First Entry";
e->e_dfp = temp;
mime7to8(header, e);
fclose(temp);
free(e);
free(header);
}
return 0;
}

After finding the crash case, I used tmin to minimize it:
0000000000000000000000=
0000000000000000000000000000000000000000=
00000000=
000000
Vulnerability#

The actual cause of the crash is quite simple: in the mime7to8 function, buf and obuf are the read and write buffers, respectively. The function does not check the pointer position when writing to obuf, causing the pointer to the next write position, obp, to "go out of bounds".
In mime7to8, the canary is overwritten due to obp going out of bounds. If there were no canary, obp would eventually move into the range of buf, causing the data that should be read to be "polluted".

sendmail#1305#
The repository provides the harness, and I rewrote it using persistent mode.
// ...
__AFL_FUZZ_INIT();
int main(){
const int MAX_MESSAGE_SIZE = 1000;
char special_char = '\377'; /* same char as 0xff. this char will get interpreted as NOCHAR */
int delim = '\0';
static char **delimptr = NULL;
char *addr;
OperatorChars = NULL;
ConfigLevel = 5;
addr = (char *) malloc(sizeof(char) * MAX_MESSAGE_SIZE);
CurEnv = (ENVELOPE *) malloc(sizeof(struct envelope));
CurEnv->e_to = (char *) malloc(MAX_MESSAGE_SIZE * sizeof(char) + 1);
#ifdef __AFL_HAVE_MANUAL_CONTROL
__AFL_INIT();
#endif
unsigned char *buf = __AFL_FUZZ_TESTCASE_BUF; // must be after __AFL_INIT
while (__AFL_LOOP(1000)) {
int len = __AFL_FUZZ_TESTCASE_LEN;
strncpy(addr, buf, len);
addr[len] = '\0';
memcpy(CurEnv->e_to, addr, len);
CurEnv->e_to[len] = '\0';
parseaddr(addr, delim, delimptr);
}
return 0;
}
In ANSWERS.md, the author points out that some global variables used in the harness code may affect the state of the program and the persistent mode, but based on my observations, only CurEnv is practically useful and closely related to the program context, and the parseaddr function only contains read operations for the unique field e_to of this variable, so my rewritten persistent mode should be feasible.
However, this time it seems that I couldn't find a crash testcase...

date#
Since I was unsure whether the main function in date.c contained global variables, I didn't dare to arbitrarily rewrite it using __AFL_LOOP. Considering that using STDIN for debugging later is also convenient, and the efficiency difference between passing test cases via STDIN and shared memory is not significant (the major efficiency impact lies in forking), I rewrote date.c into a harness as per ANSWERS.md, adding code to set env before getenv.
static char val[1024 * 16];
read(0, val, sizeof(val) - 1);
setenv("TZ", val, 1);
char const *tzstring = getenv ("TZ");
timezone_t tz = tzalloc (tzstring);

Vulnerability#
The explanation given by Savannah Git Hosting - gnulib.git/commit is that the length of the environment variable TZ exceeds ABBR_SIZE_MIN (119) on x86_64, leading to a heap memory overflow in the extend_abbr function.

I tracked it with GDB, and indeed it was in the extend_abbr function, where it attempted to add a new string after the memory allocated for tz->abbrs, causing the pointer to go out of bounds.
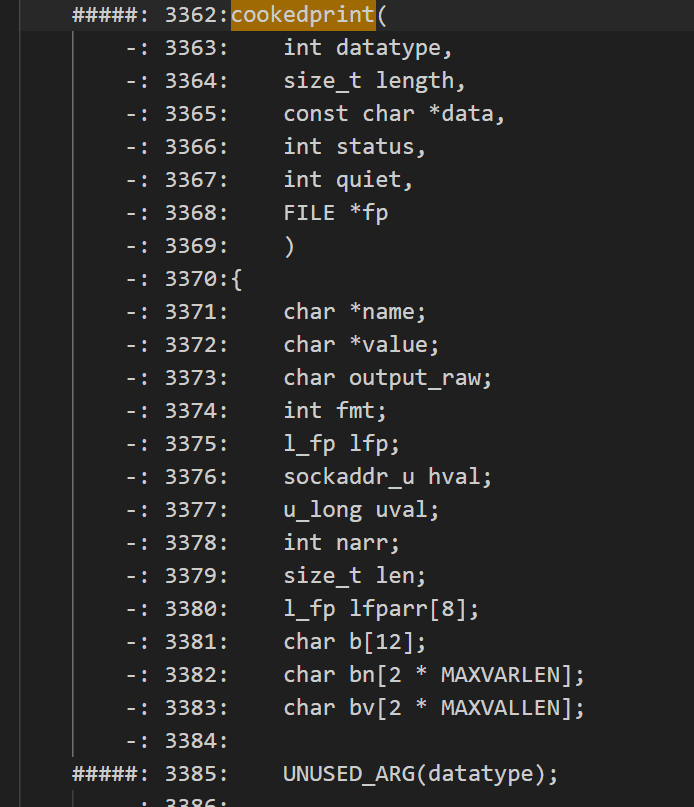
ntpq#
The vulnerability mainly exists in the cookedprint(datatype, length, data, status, stdout) function. For similar C/S pattern programs, I initially thought it was necessary to simulate normal program interaction by starting ntpd first and then fuzzing on the ntpq side, considering the logic of cookedprint. However, ANSWERS.md directly fuzzed the parameters with a semantically unrelated large string, reading it as STDIN and then splitting it into various parameters.
datatype=0;
status=0;
memset(data,0,1024*16);
read(0, &datatype, 1);
read(0, &status, 1);
length = read(0, data, 1024 * 16);
cookedprint(datatype, length, data, status, stdout);

From the perspective of code coverage, test cases under version 4.2.2 can trigger new paths and cover the cookedprint function, but they cannot cover the code under version 4.2.8p10 (##### indicates no coverage).
Summary#
AFL and its accompanying tools have indeed made fuzz testing almost "plug-and-play." To fuzz an open-source program, you only need to instrument it during compilation and write an appropriate harness program, after which you can completely "let go" and leave it to AFL.
However, I also encountered some challenges during fuzzing:
- How to improve fuzzing efficiency by all means. There is still significant room for efficiency optimization in the mutation, selection, scheduling, and execution of test cases. While attempting various challenges in AFL-training, although only one challenge did not find a crash after several hours (sendmail#1305), other programs were able to find more or less crashes in a relatively short time, but this was based on the premise that the target function and crashes were relatively simple, as the location of the vulnerabilities was known, allowing me to isolate the vulnerable functions to write harnesses. In actual situations where the vulnerabilities are unknown, further efficiency improvements are needed.
- How to analyze the crashes discovered during fuzzing. Most CVEs in AFL-training are related to memory overflow. The most straightforward understanding of overflow is that pointers point to areas beyond their intended targets, but why "out-of-bounds" situations occur requires analyzing the program's own memory allocation and access patterns. For unfamiliar programs, tools like GDB need to be used for step-by-step debugging.