昨年の 4 月に先輩に差分プライバシー(differential privacy:DP)の大きな穴に引き込まれてから、今までほぼ 1 年が経ちました。この 1 年の間、私は一人で論文を読み、アイデアを考え、実験をコードし、論文を書き、多くの遠回りをし、大小の穴に何度もつまずき、最終的に小さな論文を書き上げました。私は少し差分プライバシーに別れを告げ、他のより工学的で実証的な研究方向を探しに行きたいと思っています。
差分プライバシーに別れを告げる前に、私の心の中での差分プライバシーのイメージを振り返らせてください。
全体的に言えば、差分プライバシーは理論的に非常に強い概念です。深層学習のように「ブラックボックス」ではなく、他の工学的なプライバシー保護メカニズム(例えば Tor ネットワーク)のように明確で直感的に理解しやすいものでもなく、厳密に制限されたモデルと証明可能な確率的制約条件に基づいてプライバシー保護を実現します。
Differential Privacy#
差分プライバシーが防ぐのは差分攻撃であり、その起源はデータベースの分野にあり、攻撃者がデータベース内の具体的なデータの変化を推測するプロセスを説明します。
Model#
二者を考えます:
- データベースの管理者(curator):彼は完全なデータベース(例えばリレーショナルデータベース)を持っており、その中の各レコードはユーザーの個人情報に関するものです。彼は第三者に対して集約クエリインターフェース(関数)$f$(例えば count、sum、max)を提供します。
- 攻撃者:既存の知識に基づいて、curator が提供するインターフェースを通じてデータベース内の単一のレコードの状況を取得しようとします。
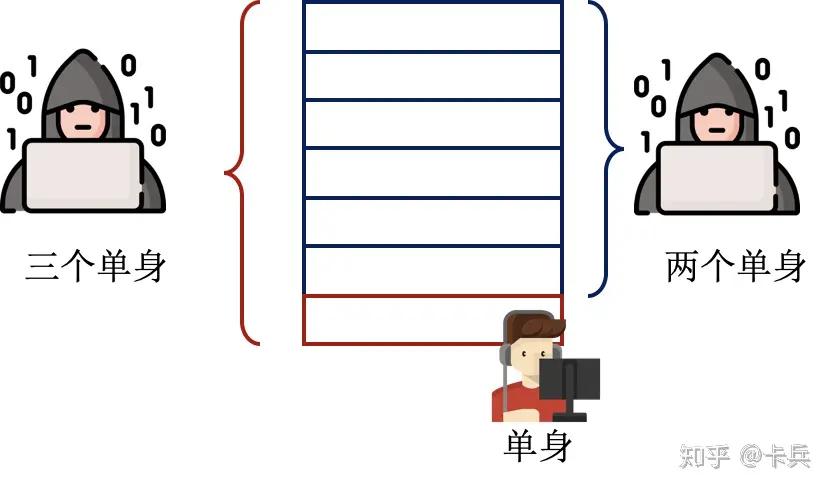
例えば、ユーザーの名前と性別を記録した表があるとします。例えば:<Alice, Female>。curator は Male の数と Female の数を問い合わせるインターフェースを提供します:
- 攻撃者は一度 Male の数を問い合わせます。
- この時、データ表が変動し、<Bob, Male> というレコードが追加されました。注意:攻撃者は Bob がデータベースに追加されたことを知っているが、彼の性別は知らない。攻撃者はこの情報を知りたいと思っています。
- 攻撃者は再度 Male の数を問い合わせ、二回の問い合わせで得られた結果を引き算することで、Bob の性別を判断できます。
知乎の普及文 Differential Privacy の紹介 では、類似の例が挙げられています。
Definition#
プライバシーの定義に関する見解は多様であり、一般的な解釈の一つは具体的なユーザーを「群衆の中に隠す」ことです。例えば、古典的な k - 匿名アルゴリズムは、集合内に少なくとも k 件のレコードが同じ値を持つことを要求します。差分プライバシーの要求も似ていますが、差分プライバシーはランダムアルゴリズムが与えられた入力と出力の確率が近いことを要求します。
**(differential privacy)** 任意の二つの隣接データセット $X$ と $X'$(隣接は上記のようにユーザーデータを一件追加する場合を指し、もちろん他にもより抽象的な解釈があります)、ランダムアルゴリズム $\mathcal {M}$ が、任意の可能な結果 $y$ に対して
が成り立つとき、ランダムアルゴリズム $\mathcal {M}$ は $\epsilon$-differential privacy($\epsilon$-DP)を満たすと呼ばれます。要するに、差分プライバシーは同じ結果を返す確率が近いことを要求します。明らかに、上記で言及された集約関数 $f$(count、sum、max)はここでの $\mathcal {M}$ に対応しており、集約関数が提供する結果は確定的であり、ランダム性を含まないため、$\epsilon$-DP を満たしません。
k - 匿名と似て、差分プライバシーはプライバシーの定義を提供しますが、差分プライバシーを実現する方法は研究者が $\mathcal {M}$ のアルゴリズムを設計する必要があります。
Mechanism#
$f$ を改造するのは実際には非常に簡単で、関数の計算過程にいくつかのランダム性を追加するだけです。実際、ほぼすべての差分プライバシー保護メカニズム $\mathcal {M}$ は「ランダム性を追加する」という核心に基づいて展開されています。
一般的なランダム性を追加する方法には主に二つの大きなカテゴリがあります:
- 変数にランダムノイズを追加すること、例えばラプラスノイズやガウスノイズ、つまり
ここで $\Delta f$ は $f$ の感度を表し、任意の二つの異なる $X$ における $f$ の差の最大値を示します。
- ランダムレスポンス(random response)を使用すること、つまりコインを投げる方法でプログラムの実行フローを決定することができます。これはランダムな if 分岐文のように考えることができます。
Properties#
差分プライバシーには、既存のアルゴリズムに基づいて組み合わせや拡張を行い、新しい差分プライバシーの擾乱アルゴリズムを形成するのに便利な特性があります。

Local Differential Privacy#
Model#
ユーザーのプライバシーが差分プライバシーの保証を受けるためには、これらの curator がアルゴリズムを修正し、ランダム性を追加する必要があります。現実の生活では、データベースの保持者(curator)はしばしばサービスを提供する企業であり、彼らがユーザーのプライバシーを保護できると信頼するのは現実的ではありません。彼らが完全なデータをパッケージ化して第三者に売ることはありません。
したがって、研究者はより厳格な要求を提案しました —— ローカル差分プライバシー(local differential privacy)。彼は自分以外のすべての人を潜在的な攻撃者と見なします。
**(local differential privacy)** 任意の(arbitrary)二つのデータ $x$ と $x'$(ここでは二つの隣接データセットではなく、単一のユーザーが一つのレコードに対応する場合)、ランダムアルゴリズム $\mathcal {M}$ が、任意の可能な結果 $y$ に対して
が成り立つとき、ランダムアルゴリズム $\mathcal {M}$ は $\epsilon$-local differential privacy($\epsilon$-LDP)を満たすと呼ばれます。DP との最大の違いは、LDP はクライアント上のアルゴリズム $\mathcal {M}$ に要求を課すことです。DP モデルでは、データベースに到達するのはユーザーの実際のデータですが、LDP モデルでは、ユーザーが送信するのはすでに $\mathcal {M}$ によって処理された偽(pseudo)データ(つまり公式中の $y$)です。
明らかに、LDP はプライバシー保護に要求があるユーザーをより満足させることができます。なぜなら、宇宙の中で、彼自身を除いて、誰も本当のデータを知らないからです。
Privacy Utility Tradeoff#
プライバシー(privacy)と効用(utility)は二つの相対的な概念であり、天秤の両端です。効用はデータが提供できる使用価値を反映します。プライバシー保護の目的でユーザーのデータに一定の修正を加えると、データに偏りが生じ、サービスの質に影響を与えます。例えば、位置情報サービス(LBS)アプリケーションでは、ユーザーはサービスを享受するために地理的位置をアップロードする必要があります(デリバリー、ライドシェア、ナビゲーション)。サービス提供者がユーザーがアップロードした偽の位置(pseudo location)に基づいてサービスを提供する場合、必然的にいくつかの問題が生じます(例えば、デリバリーが間違った場所に送られるなど)。
したがって、プライバシーを保証しつつ、あまり大きな効用を失わないことが特に重要です。これはプライバシー問題を研究する際に考慮すべき核心的な問題です。学術論文では、プライバシーの利益と効用の損失について理論的に分析するだけでなく、これら二つの変化を実験評価(empirically)するための指標(metric)を定義する必要があります。
効用に関しては、具体的な効用の測定はデータの種類と使用方法に依存します。
- 数値データ
- 平均などの統計量を計算します。
- 区間統計(ヒストグラム)。
- カテゴリデータ
- 頻度統計。
- 最も頻度の高いカテゴリ(多数派のカテゴリ)を見つけます。
- (その他)位置データ
- 近くの PoI(レストラン、公園、ホテルなど)を検索します。
- 位置情報サービス。
異なるアプリケーションに対して、効用損失の計算方法は異なり、具体的な状況に応じて分析する必要があります。しばしば、あるアルゴリズムがプライバシーを保証しつつ、特定のアプリケーションシナリオにおいて効用損失がそれほど大きくないことが確認できれば、それだけでも非常に良いことです。もちろん、ここでの損失の大きさの評価は絶対値ではなく、複数の異なるアルゴリズムの相対的な大きさや、倍率(漸近的な複雑性に似た概念)を用いて評価することができます。
Application#
LDP の適用は、モバイルインターネット時代のユーザー体験に非常に適しています。一般のユーザーは、サービス提供者があまり信頼できないことを認識しているため、保護措置がクライアント側で行われる場合の方が安全です。一部の専門的なスキルを持つユーザーは、クライアントが送信するデータが処理されたものであるかどうかをテストすることもあります(例えば、パケットキャプチャなど)。

いくつかのソフトウェアサービス会社は、自社のサービス品質を改善する目的で、ユーザーの使用データを収集します。比較的正式な大手企業は、「匿名の使用データを収集することを許可しますか?」というダイアログボックスを表示し、ユーザーに選択させます。これらのデータは、特定の機能の使用頻度などの情報を分析するために使用されます。例えば、Apple は Emoji の使用頻度を統計し、毎年すべてのユーザーの使用報告を提供します。このプロセスは、カテゴリデータの統計プロセスとして抽象化できます。ユーザーが Emoji を使用するプライバシーが差分プライバシーで保護されることを保証するために、Apple はデータをローカルとサーバーで非常に複雑に処理します。具体的なプロセスは、Learning with Privacy at Scale - Apple Machine Learning Researchという文書に公開されています。

また、Google も LDP を適用するための方案RAPPORを発表しています。

これら二社の LDP 方案のクライアント部分は非常に似ており、二つの点に要約できます:
- まず、ハッシュ関数を使用して元のデータをバイナリ列にエンコードします。
- ランダムレスポンスを使用して各バイナリビットを反転させます。
もちろん、単一のデータがこれらの処理ステップを経ると、しばしば「面目全非」になりますが、大量の面目全非のデータがサーバーに収集されると、サーバーは特定のアルゴリズムを通じて、実際の値(頻度、ヒストグラムなど)に比較的近い推定値を得ることができます。
現在の研究文献では、LDP を生産環境に適用したのは Google、Apple、Microsoft の三社であり、これは LDP の欠点の一つでもあります —— 良好な効用を得るためには、非常に大きなデータ量が必要です。
Location Privacy

LDP のもう一つの一般的な適用は地理位置サービスであり、LBS の枠組みの中で、LDP は任意の二つの位置が同じ位置に混同される確率が近いことを要求しますが、北京とロンドンの二つの位置が上海に混同される確率が近いことを求めると、巨大な効用損失を引き起こすため、比較的よく使用される方法はGeo-Indistinguishabilityという文書で述べられています:
確率の類似性は二つの位置間の距離に直接関連しています。このように、ユーザーの実際の位置を中心に、半径 $r$ の領域内のすべての位置は等価類と見なすことができ、この等価類内の各位置がユーザーの実際の位置に混同される確率は近いということです。これは上図で言う「ぼやけた位置」の範囲です。
Inference Attack#
DP に言及する際には推論攻撃(inference attack)を避けて通れません。攻撃者は既存の先験的知識 $\pi$ と公開された混同メカニズム $\mathcal {M}$ に基づいて、ユーザーの実際のデータの可能な分布を推測します。注意すべきは、(L)DP は推論攻撃を防ぐことができないということです。なぜなら、推論攻撃は攻撃者が $\pi$ を持っていると仮定しており、DP は $\pi$ とは完全に無関係だからです。実際、DP の利点は、任意の $\pi$ の下でも適用できることにあります。攻撃者がすでに実際のデータを把握していると仮定すると、つまり $\pi (x_0)=1$ であれば、DP の要求がどれほど厳しくても、攻撃者は正しい答えを出すことができます。
DP の役割は、$\mathcal {M}$ 自体に基づいて、攻撃者が追加の情報(information gain)を得ることができないことです。なぜなら、$\mathcal {M}$ によるデータの混同はランダム性を伴い、このランダムな確率は非常に「均一」であるため、攻撃者は $\mathcal {M}$ だけでは実際のデータを正確に逆推測することができないからです。しかし、これは攻撃者が他の情報を利用してデータを正確に逆推測できないことを意味するわけではありません。
すでにいくつかの論文が差分プライバシーの具体的な適用シナリオにおける限界を分析しています。例えば、地理位置プライバシー保護に関しては以下のような問題があります:
- 推論攻撃に対抗できない:例えばPIVE。
- ランダム性による効用損失の極端な状況:例えばBack to the Drawing Board。
How to Water Paper#
私の DP に関する学術研究の理解に基づいて、DP 関連の論文の難易度は以下のように減少します:
- 新しい DP モデル(scheme)または基礎的な方法を提案すること、例えばシャッフルモデル、再サンプリングによる増幅、ベクトル DP など。この種の論文は非常に強い数学的基礎が必要で、さまざまな上下界を導出する必要があります。
- DP の欠陥を掘り起こした後、DP と他のプライバシー保護概念を結びつけること。この種の問題は通常、プライバシーと効用の理解をより試されます。
- DP を具体的なアプリケーションに導入すること、例えば LBS、群知能、フェデレートラーニングなど、最適化問題の制約条件として使用するか、より先進的な DP モデルを用いて既存の工学的実践を改善し、理論分析を補足します(公式を適用)。
Summary#
DP は理論的に非常に強い概念であり、データ処理プロセス $\mathcal {M}$ のランダム性に対して厳格な制約を課し、任意の二つの入力が同じ出力を返す確率が近いことを要求します。他のプライバシー概念と比べて、DP はユーザーにとって理解しにくく、プライバシー保護の効果(パラメータの変化を含む)を明確かつ直感的に説明することは困難です。