mykter/afl-training 包含能幫助初學者快速掌握如何使用 afl++ 對開源軟體進行模糊測試的一系列材料。
Setup#
考慮到將構建好的 ghcr.io/mykter/fuzz-training 直接 pull 下來所花的時間可能會更長,我選擇在本地通過 Dockerfile 從頭開始 build image,然後運行容器。
- build:可以在 Dockerfile 中添加
ARG http_proxy,然後在 docker build 命令中添加--build-arg "http_proxy=http://127.0.0.1:7890",同時配置參數--network=host(和 docker run--net=host不一樣!),使得 build 過程能夠連接網路代理。在 Dockerfile 中合適的位置添加 git 代理(git config --global http-proxy $http_proxy),加快 git pull 的速度。 - run:由於訪問外網和科學上網的代理程序都運行在 host 上,而我的容器在運行時始終無法連通 host 的 ip(應該是 172.27.0.1)和代理端口,於是只能選擇讓容器運行在 host 模式下(
--net=host),免去考慮端口映射、host ip 等麻煩。
libxml2#
libxml2 是一個流行的 XML 處理庫,使用 C 語言實現,其具有的以下特點使其非常適合用於練習 fuzz:
- 無狀態
- 無網路通信和文件讀寫
- 文檔詳細豐富,API 外顯,無需額外分析內部的 fuzz 接口
- 功能集中、簡單(處理 XML),運行較快
這裡考慮的 CVE(Common Vulnerabilities & Exposures)是 CVE-2015-8317:在 parser.c 中的 xmlParseXMLDecl 函數在處理 不完整的 encoding 以及 不完整的 XML 聲明 時會觸發 out-of-bounds heap read。
/**
* xmlParseXMLDecl:
* @ctxt: an XML parser context
*
* parse an XML declaration header
*
* [23] XMLDecl ::= '<?xml' VersionInfo EncodingDecl? SDDecl? S? '?>'
*/
void xmlParseXMLDecl(xmlParserCtxtPtr ctxt) { ... }
在 parser.c 中 xmlParseXMLDecl 函數就是負責解析 XML 聲明部分的,XML 聲明指的就是一般放在 XML 文檔第一行的內容:
<?xml version="1.0" encoding="UTF-8"?>
思路#
雖說問題出在這個函數功能內部,但是倒也沒必要僅測試該函數:
- 我自我感覺,由不完整的字符串取值導致的 XML 聲明解析操作的薄弱性,在 fuzz 過程中應該是不難發現的,生成僅包含聲明的 XML 文檔和完整的 XML 文檔,分別進行 fuzz 的效率的差異應該不會過大。
xmlParseXMLDecl函數的參數是 XML 解析過程的 context(xmlParserCtxtPtr),直接生成和變異此 context 是一件非常麻煩且低效的事情,此 context 應由更高級的 API 生成。
基於這兩點考慮,我找到了和 xmlParserCtxtPtr 相關的示例程序,作為 fuzz 的 harness:
#include <stdio.h>
#include <libxml/parser.h>
#include <libxml/tree.h>
/**
* exampleFunc:
* @filename: a filename or an URL
*
* Parse and validate the resource and free the resulting tree
*/
static void exampleFunc(const char *filename) {
xmlParserCtxtPtr ctxt; /* the parser context */
xmlDocPtr doc; /* the resulting document tree */
/* create a parser context */
ctxt = xmlNewParserCtxt();
if (ctxt == NULL) {
fprintf(stderr, "Failed to allocate parser context\n");
return;
}
/* parse the file, activating the DTD validation option */
doc = xmlCtxtReadFile(ctxt, filename, NULL, XML_PARSE_DTDVALID);
/* check if parsing succeeded */
if (doc == NULL) {
fprintf(stderr, "Failed to parse %s\n", filename);
} else {
/* check if validation succeeded */
if (ctxt->valid == 0)
fprintf(stderr, "Failed to validate %s\n", filename);
/* free up the resulting document */
xmlFreeDoc(doc);
}
/* free up the parser context */
xmlFreeParserCtxt(ctxt);
}
int main(int argc, char **argv) {
if (argc != 2)
return(1);
/*
* this initialize the library and check potential ABI mismatches
* between the version it was compiled for and the actual shared
* library used.
*/
LIBXML_TEST_VERSION
exampleFunc(argv[1]);
/*
* Cleanup function for the XML library.
*/
xmlCleanupParser();
/*
* this is to debug memory for regression tests
*/
xmlMemoryDump();
return(0);
}
程序邏輯極為簡單,先從命令行參數中讀取一個 filename,構造一個全新的 xmlParserCtxtPtr 實例,然後從 filename 中去文本並解析,解析的過程由 xmlParserCtxtPtr 實例追蹤。
接著編譯 libxml2 的庫和 harness 可執行程序:
cd libxml2
CC=afl-clang-fast ./autogen.sh
AFL_USE_ASAN=1 make -j 4
cd ..
AFL_USE_ASAN=1 afl-clang-fast ./harness.c -I libxml2/include libxml2/.libs/libxml2.a -lz -lm -o fuzzer
然後開始 fuzz:
AFL_SKIP_CPUFREQ=1 afl-fuzz -i inputs/ -o outputs/ ./fuzzer @@
Fuzz result#


Persistent Mode#
參考答案中給出的 harness 使用了 AFL-LLVM 的 Persistent Mode。
在最基礎的 AFL 中,fuzzer 主程序會 fork 一個子進程作為 fork_server。fuzz 過程不可避免多次執行目標(target)程序,為了避免多次 exec 裝載目標程序帶來的系統開銷,AFL 讓 fork_server 執行 fork 命令來產生新的 target。
為了進一步降低 fork 帶來的開銷,persistent mode 允許 harness 代碼中顯式地循環調用被測 API,即在 harness 的 main 函數中以這樣的形式進行:
while (__AFL_LOOP(1000)) {
/* Setup function call, e.g. struct target *tmp = libtarget_init() */
/* Call function to be fuzzed, e.g.: */
target_function(buf, len);
/* Reset state. e.g. libtarget_free(tmp) */
}
編譯的 XML 文檔由內存中產生,完全可以省去寫入文件的操作,直接輸入到 fuzzer 中。在 AFL 中,測試用例經過文件重定向到 STDIN,然後由 target 程序讀取。AFL++ 提供了共享內存通道,實現 fuzzer 和 target 之間的測試用例傳遞。要利用這一特性,只需要聲明 __AFL_FUZZ_INIT(); 這個宏即可。
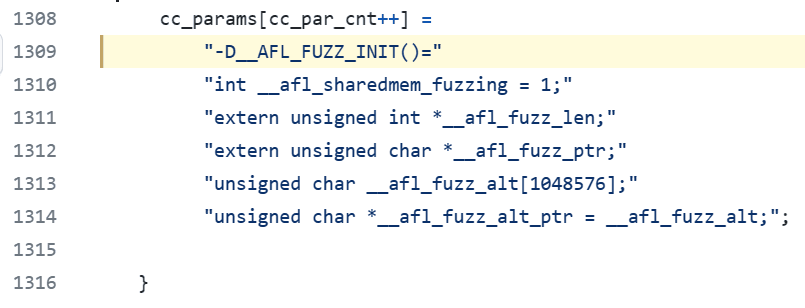
此外,雖然通過 persistent mode 能夠避免每次都執行 target 的初始化代碼,但是這些初始化代碼依然會在 fork_server fork target 進程時被執行。為了復用程序運行了這些初始化代碼之後的狀態,AFL++ 的方法是將 fork server 的初始化(從原本的程序開頭)延遲到用戶指定位置。
/* This one can be called from user code when deferred forkserver mode
is enabled. */
void __afl_manual_init(void) {
static u8 init_done;
if (...) {...}
if (!init_done) {
__afl_start_forkserver();
init_done = 1;
}
}
結合上述三個特性:persistent mode,共享內存 fuzzing 和延遲初始化,最終組成了 libxml2 的 harness。其中 __AFL_FUZZ_TESTCASE_BUF 和 __AFL_FUZZ_TESTCASE_LEN 這兩個宏分別表示共享內存地址和用例所占內存大小。
#include "libxml/parser.h"
#include "libxml/tree.h"
#include <unistd.h>
__AFL_FUZZ_INIT();
int main(int argc, char **argv) {
#ifdef __AFL_HAVE_MANUAL_CONTROL
__AFL_INIT();
#endif
unsigned char *buf = __AFL_FUZZ_TESTCASE_BUF; // must be after __AFL_INIT
xmlInitParser();
while (__AFL_LOOP(1000)) {
int len = __AFL_FUZZ_TESTCASE_LEN;
xmlDocPtr doc = xmlReadMemory((char *)buf, len, "https://mykter.com", NULL, 0);
if (doc != NULL) {
xmlFreeDoc(doc);
}
}
xmlCleanupParser();
return(0);
}
借助 AFL 自帶的 XML dictionary ,在獲知一定語法的情況下進行輸入文檔的變異,能夠進一步提升效率:
AFL_SKIP_CPUFREQ=1 afl-fuzz -i inputs/ -o outputs/ -x ~/AFLplusplus/dictionaries/xml.dict ./fuzzer


最後找到的 crash 用例其實數量挺多的,其中也確實有 CVE 所描述的 unterminated encoding value。
Heartbleed#
CVE-2014-0160是曾經非常著名的 “心臟滴血”(heartbleed)漏洞,這個漏洞存在於 OpenSSL 1.0.1g 之前的 1.0.1 版本中。
為了加快 fuzz 進度,我在改造 handshake.cc 的過程中融入了 persistent mode、shared memory 和 deferred initialization。
#include <openssl/ssl.h>
#include <openssl/err.h>
#include <assert.h>
#include <stdint.h>
#include <stddef.h>
#include <unistd.h>
#ifndef CERT_PATH
# define CERT_PATH
#endif
__AFL_FUZZ_INIT();
SSL_CTX *Init() {
SSL_library_init();
SSL_load_error_strings();
ERR_load_BIO_strings();
OpenSSL_add_all_algorithms();
SSL_CTX *sctx;
assert (sctx = SSL_CTX_new(TLSv1_method()));
/* These two file were created with this command:
openssl req -x509 -newkey rsa:512 -keyout server.key \
-out server.pem -days 9999 -nodes -subj /CN=a/
*/
assert(SSL_CTX_use_certificate_file(sctx, "server.pem",
SSL_FILETYPE_PEM));
assert(SSL_CTX_use_PrivateKey_file(sctx, "server.key",
SSL_FILETYPE_PEM));
return sctx;
}
int main() {
SSL_CTX *sctx = Init();
#ifdef __AFL_HAVE_MANUAL_CONTROL
__AFL_INIT();
#endif
unsigned char *buf = __AFL_FUZZ_TESTCASE_BUF;
while (__AFL_LOOP(1000))
{
SSL *server = SSL_new(sctx);
BIO *sinbio = BIO_new(BIO_s_mem());
BIO *soutbio = BIO_new(BIO_s_mem());
SSL_set_bio(server, sinbio, soutbio);
SSL_set_accept_state(server);
/* TODO: To spoof one end of the handshake, we need to write data to sinbio
* here */
int len = __AFL_FUZZ_TESTCASE_LEN;
BIO_write(sinbio, buf, len);
SSL_do_handshake(server);
SSL_free(server);
}
SSL_CTX_free(sctx);
return 0;
}
fuzz 的結果如圖所示,懷疑 stability 較低可能於復用 SSL Context 有關。


Vulnerability#
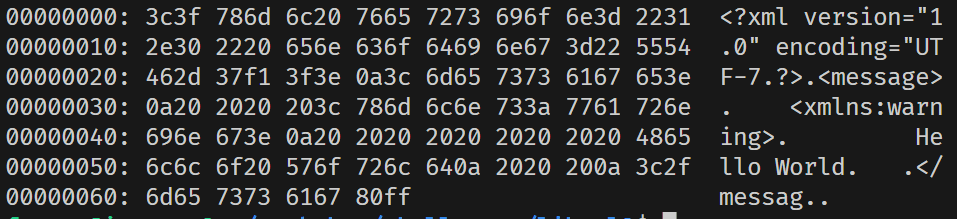
通過 xxd 命令可以 16 進制格式輸出文件數據(據說 xxd 更強大的功能是支持將修改後的數據 dump 到文件裡)。
![]()

- byte 0:SSL 數據包類型,這裡 18 對應 TLS1_RT_HEARTBEAT。
- byte 1-2:SSL 版本,這裡 0301 代表 TLS1.0,0302 代表 1.1,0303 代表 1.2,這裡的 03f5 因該是 fuzzer 自動生成的版本號,可能沒有實際的版本與之對應,但是 TLS server 由於一些 fallback 的邏輯使得其依然能夠接受這樣的版本號。
- byte 3-4:TLS 完整數據包(包括頭部)的長度,這裡的 0005 應該也是 fuzzer 生成的,不合理,但是該漏洞的核心問題不是出在這裡。
- byte 5:TLS heartbeat 類型,1 對應 request,2 對應 response。這裡是從客戶端發送給服務端的,所以是 1。
- byte 6:heartbeat payload 長度。
- 其他:heart payload 數據,數據長度要符合 byte 6。
按照正常的處理邏輯,server 會回顯(echo)request 的 payload length 和 data,簡化後的代碼邏輯為:
int
tls1_process_heartbeat(SSL *s) {
unsigned char *p = &s->s3->rrec.data[0], *pl;
/* Read type and payload length first */
hbtype = *p++;
n2s(p, payload);
pl = p;
if (hbtype == TLS1_HB_REQUEST) {
/* Allocate memory for the response, size is 1 bytes
* message type, plus 2 bytes payload length, plus
* payload, plus padding
*/
buffer = OPENSSL_malloc(1 + 2 + payload + padding);
bp = buffer;
/* Enter response type, length and copy payload */
*bp++ = TLS1_HB_RESPONSE;
s2n(payload, bp);
memcpy(bp, pl, payload);
}
}
如果攻擊者給定一個較大的 payload length,而沒有給出足夠的 payload data,那麼 server 會根據 payload length 來開辟 response 的緩衝區,並且從 payload data 緩衝區拷貝 payload length 長度的數據到 response 緩衝區,結果就是 payload length 緊接著之後的內存中的數據會洩露到 response 中,發送給攻擊者。
sendmail#1301#
需要測試的漏洞是 CVE-1999-0206。代碼倉庫中已經給出了 main.c 作為 harness 代碼,測試的目標函數為 mime7to8。這個函數的作用是將 base64 編碼或者 quoted-printable 編碼的文本解析成實際數據。
- base64:用 64 個字符(6bit)來表達二進制數據,也就是 3 byte 的數據需要用 4 個字符來編碼。
- quoted-printable:對於不可打印的 ASCII 字符,將其 16 進制的字符表示前加上等號,用三個字符來編碼。

AFL-training 推薦在 fuzz 時使用 persistent mode 和 multicore 並行。由於 ENVELOPE 結構中貌似沒有能夠直接存放字符串的數據成員,而是必須要指定一個 temporary filename,因此這裡應該是不能用 shared memory 直接傳遞測試用例的。
除了 shared memory,deferred initialization 似乎也無法起到太大作用,因為初始化部分代碼看起來挺簡單的,用不了多少時間,所以我只使用了 __AFL_LOOP。
#include "my-sendmail.h"
#include <assert.h>
int main(int argc, char **argv)
{
HDR *header;
register ENVELOPE *e;
FILE *temp;
while (__AFL_LOOP(1000))
{
temp = fopen(argv[1], "r");
assert(temp != NULL);
header = (HDR *)malloc(sizeof(struct header));
header->h_field = "Content-Transfer-Encoding";
header->h_value = "quoted-printable";
header->h_link = NULL;
header->h_flags = 0;
e = (ENVELOPE *)malloc(sizeof(struct envelope));
e->e_id = "First Entry";
e->e_dfp = temp;
mime7to8(header, e);
fclose(temp);
free(e);
free(header);
}
return 0;
}

在尋找到產生 crash 的用例之後,用 tmin 進行精簡:
0000000000000000000000=
0000000000000000000000000000000000000000=
00000000=
000000
Vulnerability#

實際導致 crash 的問題很簡單,在 mime7to8 函數中,buf 和 obuf 分別是讀和寫的緩衝區,該函數在寫 obuf 時沒有對指針位置進行校驗,導致指向下個寫位置的 obp “出界”。
在 mime7to8 中,canary 就是因為 obp 出界,導致其內容被覆蓋了。若是沒有 canary,那麼 obp 最終會移動到 buf 的範圍內,導致本應讀的數據受到 “污染”。

sendmail#1305#
倉庫中提供了 harness,我借用 persistent mode 將其改寫。
// ...
__AFL_FUZZ_INIT();
int main(){
const int MAX_MESSAGE_SIZE = 1000;
char special_char = '\377'; /* same char as 0xff. this char will get interpreted as NOCHAR */
int delim = '\0';
static char **delimptr = NULL;
char *addr;
OperatorChars = NULL;
ConfigLevel = 5;
addr = (char *) malloc(sizeof(char) * MAX_MESSAGE_SIZE);
CurEnv = (ENVELOPE *) malloc(sizeof(struct envelope));
CurEnv->e_to = (char *) malloc(MAX_MESSAGE_SIZE * sizeof(char) + 1);
#ifdef __AFL_HAVE_MANUAL_CONTROL
__AFL_INIT();
#endif
unsigned char *buf = __AFL_FUZZ_TESTCASE_BUF; // must be after __AFL_INIT
while (__AFL_LOOP(1000)) {
int len = __AFL_FUZZ_TESTCASE_LEN;
strncpy(addr, buf, len);
addr[len] = '\0';
memcpy(CurEnv->e_to, addr, len);
CurEnv->e_to[len] = '\0';
parseaddr(addr, delim, delimptr);
}
return 0;
}
在 ANSWERS.md 中,作者提示 harness 的代碼中用到了一些全局變量,這些變量可能會成為程序的狀態,對 persistent mode 產生影響,但是根據我的觀察,只有 CurEnv 是起實際用途且與程序上下文密切相關的變量,而且 parseaddr 函數也僅包含對該變量唯一一個字段 e_to 的讀操作,所以我自己改寫的 persistent mode 應該是可行的。
然而這次貌似找不到 crash testcase 了。。。

date#
由於不知道 date.c 的 main 函數是否存在全局變量,因此我不敢隨意用 __AFL_LOOP 改寫,考慮到後續調試時用 STDIN 也比較方便,且用 STDIN 傳入用例和 shared memory 傳入用例的效率差距不大(影響效率的大頭在 fork 上面),所以按照 ANSWERS.md 將 date.c 改寫為 harness,在 getenv 之前添加了設置 env 的代碼。
static char val[1024 * 16];
read(0, val, sizeof(val) - 1);
setenv("TZ", val, 1);
char const *tzstring = getenv ("TZ");
timezone_t tz = tzalloc (tzstring);

Vulnerability#
Savannah Git Hosting - gnulib.git/commit 給出的解釋是環境變量 TZ 的長度超過了 ABBR_SIZE_MIN (119) on x86_64,導致 extend_abbr 函數中會出現堆內存溢出的情況。

我用 GDB 跟蹤了一下,確實是 extend_abbr 函數中,試圖在 tzalloc 分配的 tz->abbrs 內存之後添加新的字符串,導致指針越界。
ntpq#
漏洞主要存在於 cookedprint(datatype, length, data, status, stdout) 函數中。對於類似的 C/S 模式的程序,我原以為需要模擬正常程序交互,先啟動 ntpd 之後再在 ntpq 端進行 fuzz,考慮 cookedprint 的程序邏輯。結果 ANSWERS.md 中直接對參數進行了語義無關的 fuzz,即變異一個大的字符串作為 STDIN,然後拆分成各個參數。
datatype=0;
status=0;
memset(data,0,1024*16);
read(0, &datatype, 1);
read(0, &status, 1);
length = read(0, data, 1024 * 16);
cookedprint(datatype, length, data, status, stdout);

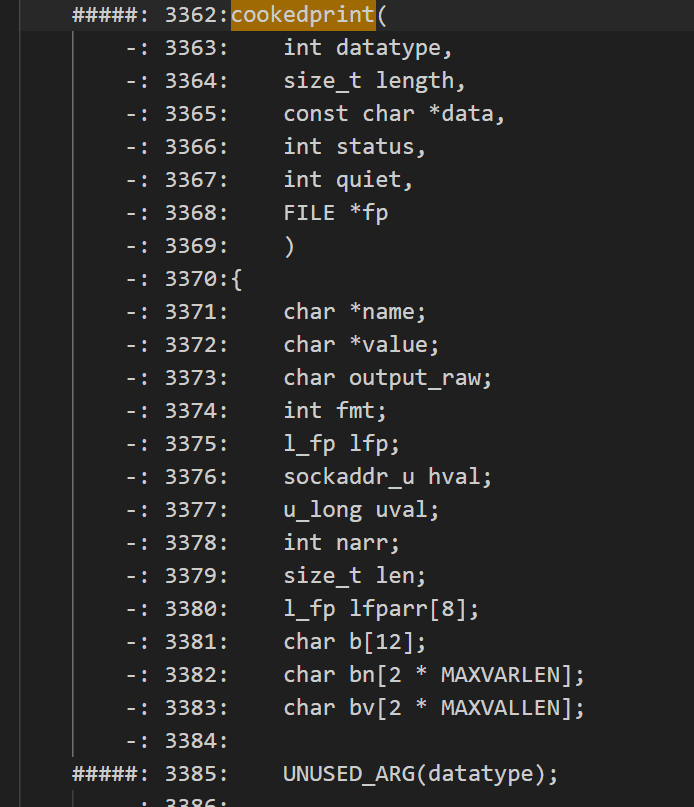
從代碼覆蓋率的角度看, 4.2.2 版本下能夠觸發新路徑的用例,覆蓋了 cookedprint 函數,但是不能覆蓋 4.2.8p10 版本下的代碼(##### 代表沒有覆蓋)。
Summary#
AFL 及其配套工具確實將模糊測試實現成了幾乎 “開箱即用” 的程度,要 fuzz 一個開源程序,只需要在編譯時進行插桿,然後編寫恰當的 harness 程序,剩下就可以完全 “撒手” 交給 AFL。
但是我在 fuzz 時也遇到了一些難題問題:
- 如何千方百計提高 fuzz 的效率。在用例的變異、選擇、調度、執行過程中,還存在很大的效率優化空間。我在嘗試 AFL-training 中的各個 challenge 時,雖然只有一個 challenge 在經過了十幾個小時之後依然沒有發現 crash(sendmail#1305),其他程序都能在較短的時間內發現或多或少的 crash,但是這是建立在目標函數和 crash 都較為簡單的前提下的,因為漏洞的位置已知,所以可以把存在漏洞的函數單獨拿出來編寫 harness。在漏洞未知的實際情況下,需要進一步提高效率。
- 如何分析 fuzz 過程中發現的 crash。AFL-training 中大部分 CVE 都是和內存溢出(overflow)相關的。對溢出最直白的理解就是指針指向了超出其應該指向的區域,但是為何會產生 “越界” 的情況,需要結合程序自身的內存分配、訪問模式進行分析。對於不熟悉的程序,需要借助 GDB 等工具單步調試。